GeneClust JS User’s Guide
Description
Gene Shaving is a method for clustering groups of similarly behaving genes whose changes in expression are most tightly linked to observed biological changes. The basic method is similar to observed principal components (singular value decomposition, maximum eigenvalue, etc.) with a sequential twist: a canonical “gene vector” is identified based on the eigenvectors, and the genes are ranked according to their agreement with this vector. The worst fitting are then “shaved off” and a new canonical vector is identified and fit.
The GeneClust distribution is a denovo implementation of the Gene Shaving method. Geneclust JS is a Javascript implementation of the GeneClust package that runs right in your browser, so there is no need to install any software.
You must be using a relatively modern browser, however. Recent versions of Chrome and Firefox are known to work. When the Geneclust JS page is loaded, it checks that your browser has the necessary capabilities. If it displays a warning alert, please upgrade to a more modern browser.
Input Data Formats
To use Geneclust JS, you must have an input data file containing the array data to analyze and, optionally, a supervision file assigning each sample to a sample class.
The array data must be stored in a tab-separated (tsv) file, with input lines corresponding to variables (e.g. genes) and columns to data points (e.g. samples). The first line must be a header containing the names of each column in the subsequent data lines. Each subsequent line corresponds to one row of the input data matrix. The first column of each data line must contain the name of that row. The first (header) line may contain either one less column than the data lines (as often produced by R for example), or the same number of columns (in which case, the first column of the header line is ignored). Example input data files: Alon 2000, Alon 446, Alon Top, NCI 60.
The supervision data, if supplied, must consist of precisely one line for each data column in the array data file and each line must consist of exactly one class name. The classes are matched to data columns by their respective orders. Example classification data files: Alon Classification, NCI 60 Classification.
User Interface
The user interface consists of four input sections and a results section (initially empty). You should complete the input sections in order.

After you select the input data file, the browser will load the file, perform some rudimentary data checks, and summarize the results below the file chooser. A green summary line as shown below indicates that the data was loaded successfully.
After loading the classification data, if any, the browser will also display the data classes found in the classification file.
Creating Gene Shaving Clusters
If desired, modify the desired Gene Shaving parameters using the fields in the third input section. If no supervision file is loaded, or if the Percent Supervision is zero, unsupervised shaving will be performed. If Percent Supervision is 100, complete supervision will be performed, otherwise partial supervision.
In the fourth section:
- Specify the initial number of clusters to generate, and
- Press the Run Geneclust button to analyze your data.
The application will start displaying trace information below the results table to keep you informed on progress, and replace the Reset button with a Cancel button. As clusters are generated they will be added to the Results table. Note that the application is responsive to user input while Geneshaving is in progress. Geneshaving will terminate automatically when the prespecified number of clusters has been generated, or if it is unable to extract any additional clusters. You can terminate the Geneshaving process early by pressing the Cancel button. If you need to generate additional clusters, press the Run Geneclust button again.
After you have finished with this dataset, press the Reset button to clear the loaded data. Note that changes to the Geneshaving parameters are not reset.
Displaying and/or Printing Gene Shaving Clusters
After at least one cluster has been generated, the Geneshaving results produced so far can be displayed or printed. Note that these optional displays can be generated while subsequent clusters are still being generated. Canceling subsequent cluster generation will not affect already generated clusters or the ability to subsequently restart cluster generation.
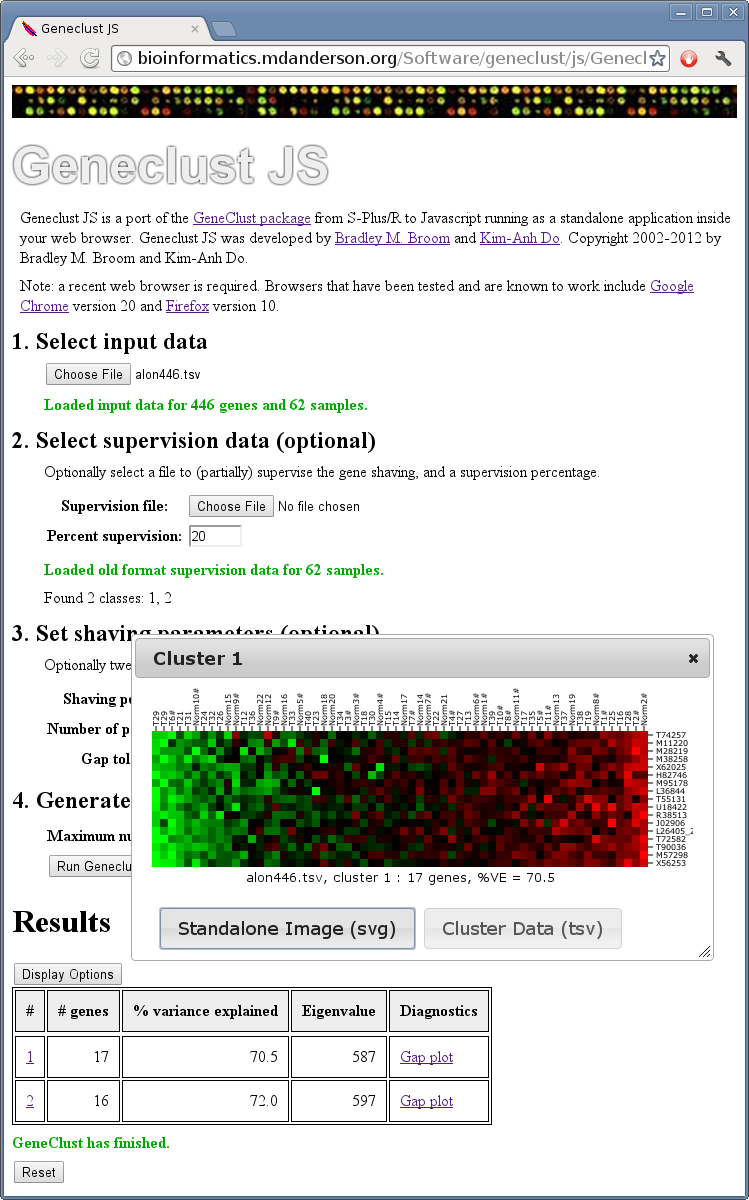
To display the cluster image for a specific cluster, click the corresponding cluster number (left most column) in the Results table. To display a diagnostic plot for that cluster, click the appropriate link in the Diagnostics column of the table. (Currently, only Gap plot is available.)
The selected cluster image or diagnostic plot will be displayed in a popup dialog box. Multiple images or plots can be displayed concurrently. You can fine tune the display (color scheme, font sizes, pixel sizes, etc.) by pressing the Display Options button just above the results table. (Note that changing the display parameters will close any currently open dialog windows.)
The cluster image or diagnostic plot can be viewed in a separate window or tab by pressing the Standalone Image button. The image or plot can be printed or saved from this new window/tab. The image can also be saved by right-clicking the Standalone Image button on the dialog window and choosing Save Link As… (or equivalent) from the popup menu. The data format of the saved image will be scalable vector graphics (SVG). Editors for SVG format graphics files (for example Inkscape) can be used to produce images in other desired formats.
Similarly, the data for a cluster can be viewed or saved using the Cluster Data button on the dialog window.